
Einige Multifunktionsdrucker sind in der Lage, eingescannte Dokumente mit einer unsichtbaren Ebene zu versehen, die die gescannte Schrift als Text enthält. Hierdurch werden eingescannte PDF Dokumente durchsuchbar für PDF Programme, Dokumentenmanagementsysteme und Suchindizes.
Sofern ihr Gerät hierzu nicht in der Lage ist oder Sie regelmäßig entsprechende Dokumente aus einer anderen Quelle erhalten, stellt sich die Frage, wie man diese zusätzliche Textebene nachträglich erstellen kann.
Hierzu bietet sich unter Windows eine Kombination aus der Texterkennung Tesseract, dem PDF Toolkit Ghostscript, der Programmiersprache Python und dem Python-Programm ocrmypdf an.
Zusammen mit einigen Batch-Skripten lässt sich hiermit über einen Rechtsklick auf ein PDF Dokument die OCR Funktion benutzen.
Laden Sie die folgenden Dateien für ihr System herunter und speichern Sie alle im gleichen Ordner:
Speichern Sie die unten stehende Batch Datei als install.bat im gleichen Ordner und führen Sie diese als Administrator aus.
Im Rahmen der Installation werden Sie u.a. gebeten, sich durch den Installer von Ghostscript und Tesseract durchzuklicken. Sie können diese Installer ohne spezifische Optionen installieren.
@echo off
:: Detect Admin Rights
echo Detect Admin rights ...
NET SESSION >nul 2>&1
IF %ERRORLEVEL% EQU 0 (
@setlocal enableextensions
@cd /d "%~dp0"
) ELSE (
ECHO PLEASE RUN AS ADMIN
pause
exit
)
:: Installing Ghostscript (Silent Install not possible anymore)
echo Installing Ghostscript (your interaction is needed)
for /r %%f in (gs*.exe) do (
%%f
)
:: Installing Tesseract
echo Installing Tesseract (your interaction is needed)
for /r %%f in (tesseract*.exe) do (
%%f /S
)
echo Copy Tesseract German Modell
copy deu.traineddata "C:\Program Files\Tesseract-OCR\tessdata\" /Y
:: Installing Python
echo Silently Installing Python ...
for /r %%f in (python*.exe) do (
%%f /quiet InstallAllUsers=1 PrependPath=1 Include_test=0 Include_launcher=0 SimpleInstall=1
)
:: Disable Max Path Limit
echo Disable Max Path Limit in Windows
reg add HKLM\SYSTEM\CurrentControlSet\Control\FileSystem /v LongPathsEnabled /t REG_DWORD /d 0x00000001 /f
:: Add OCR Context Menu to registry
echo Installing OCR Context Menue
reg add HKLM\SOFTWARE\Classes\Acrobat.Document.DC\shell\OCR\command /ve /d "\"C:\OCR\OCR.cmd\" \"%%1\"" /f
:: Copy CMD-Opener to C:\OCR
mkdir c:\OCR
echo set basename=%%1 > C:\OCR\OCR.cmd
echo ocrmypdf -l deu %%basename%% %%basename:~0,-5%%_ocr.pdf >> C:\OCR\OCR.cmd
:: Install ocrmypdf
echo Installing ocrmypdf Python bib
start /wait CMD /C pip install ocrmypdf
Um OCR auf ein PDF anzuwenden, klicken Sie mit der rechten Maustaste auf ein PDF und dann auf OCR. Mit Windows 11 ist ein Klick mehr erforderlich. Hier müssen Sie das alte Kontextmenü aufrufen über die erweiterten Optionen, oder indem Sie die Umschalt-Taste während des Rechtsklicks gedrückt halten.
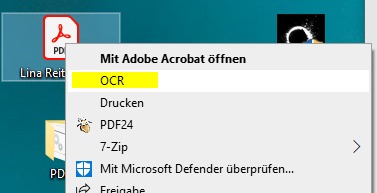
Vorher:

Nachher:
